
내맘대로 코딩
옵티마이저(Optimizer) 본문
옵티마이저 개념
- 딥러닝 학습시 최대한 틀리지 않는 방향으로 학습해야 한다,
- 얼마나 **틀리는지(loss)**를 알게 하는 함수가 **loss function(손실함수)**이다.
- loss function 의 최솟값을 찾는 것을 학습 목표로 한다.
- 최소값을 찾아가는 것 최적화 = Optimization
- 이를 수행하는 알고리즘이 최적화 알고리즘 = Optimizer 이다.

옵티마이저 종류
- Optimizer는 Learning rate나 Gradient를 어떻게 할 지에 따라 종류가 다양함

1) GD (Gradient Descent)
- Learning rate는 한 번에 얼마나 학습할지, Gradient는 어떤 방향으로 학습할지를 나타냅니다.

2) 배치 크기가 1인 확률적 경사 하강법(Stochastic Gradient Descent, SGD)
- 배치 크기가 1인 확률적 경사 하강법은 매개변수 값을 조정 시 전체 데이터가 아니라 랜덤으로 선택한 하나의 데이터에 대해서만 계산하는 방법입니다. 더 적은 데이터를 사용하므로 더 빠르게 계산할 수 있습니다.

- 위 그림에서 좌측은 배치 경사 하강법, 우측은 배치 크기가 1인 확률적 경사 하강법이 최적해를 찾아가는 모습을 보여주고 있습니다. 확률적 경사 하강법은 매개변수의 변경폭이 불안정하고, 때로는 배치 경사 하강법보다 정확도가 낮을 수도 있지만 하나의 데이터에 대해서만 메모리에 저장하면 되므로 자원이 적은 컴퓨터에서도 쉽게 사용가능 하다는 장점
3) 알엠에스프롭(RMSprop)
- RMSprop은 신경망에서 사용되는 경사 하강법 최적화 알고리즘 중 하나이다. 주로 확률적 경사 하강법(SGD)의 변형으로 사용되며, 학습률을 조절하기 위한 기법 중 하나
4) 모멘텀(Momentum)
- 모멘텀(Momentum)은 관성이라는 물리학의 법칙을 응용한 방법입니다. 모멘텀 경사 하강법에 관성을 더 해줍니다. 모멘텀은 경사 하강법에서 계산된 접선의 기울기에 한 시점 전의 접선의 기울기값을 일정한 비율만큼 반영합니다. 이렇게 하면 마치 언덕에서 공이 내려올 때, 중간에 작은 웅덩이에 빠지더라도 관성의 힘으로 넘어서는 효과를 줄 수 있습니다.

- 전체 함수에 걸쳐 최소값을 글로벌 미니멈(Global Minimum) 이라고 하고, 글로벌 미니멈이 아닌 특정 구역에서의 최소값인 로컬 미니멈(Local Minimum) 이라고 합니다. 로컬 미니멈에 도달하였을 때 글로벌 미니멈으로 잘못 인식하여 탈출하지 못하였을 상황에서 모멘텀. 즉, 관성의 힘을 빌리면 값이 조절되면서 현재의 로컬 미니멈에서 탈출하고 글로벌 미니멈 내지는 더 낮은 로컬 미니멈으로 갈 수 있는 효과를 얻을 수도 있습니다.
5) Adam (Adaptive Moment Esimation)
- Momentum 와 RMSProp 두가지를 섞어 쓴 알고리즘이다.
- 즉, 진행하던 속도에 관성을 주고, 최근 경로의 곡면의 변화량에 따른 적응적 학습률을 갖은 알고리즘이다.
- 매우 넓은 범위의 아키덱처를 가진 서로 다른 신경망에서 잘 작동한다는 것이 증명되어, 일반적 알고리즘에 현재 가장 많이 사용되고 있다.
- 아담의 강점은 bounded step size 이다.
- Momentum 방식과 유사하게 지금까지 계산해온 기울기의 지수 평균을 저장하며,
- RMSProp과 유사하게 기울기의 제곱값에 지수평균을 저장한다.

- Adam 에서는 기울기 값과 기울기의 제곱값의 지수이동평균을 활용하여 step 변화량을 조절한다.
- 또한, 초기 몇번의 update 에서 0으로 편향되어 출발 지점에서 멀리 떨어진 곳으로 이동하는, 초기 경로의 편향 문제가 있는 RMSProp의 단점을 보정하는 매커니즘이 반영되어있다. ( m 과 v가 처음에 0으로 초기화되어있기 떄문에, 학습의 초반부에서는 mt, vt, mtxVt 가 0에 가깝게 bias 되있을 것이라고 판단하여, 이를 unbiased 하게 만들어주는 작업을 거친다.)
- 보정을 통해 unbiased 된 expectation을 얻을 수 있다.


hyper-parameter는 각각 아래 값들이 추천된다.
!https://velog.velcdn.com/images/freesky/post/c63fdc9c-857e-49a1-844a-8e86300267a3/image.png
보통 β1, β2, ϵ 값은 고정 시켜두고, 에타를 여러 값으로 시도해가면서 가장 잘 작동되는 최적의 값을 찾는다.
[출처]
- https://velog.io/@freesky/Optimizer
- https://medium.com/cdri/optimizer에-대한-전반적인-이해-633d8ec9ac1b
- https://wikidocs.net/36033
07-04 딥 러닝의 학습 방법
딥 러닝의 학습 방법의 이해를 위해 필요한 개념인 손실 함수, 옵티마이저, 에포크의 개념에 대해서 정리합니다. ## 1. 손실 함수(Loss function) ' 카테고리의 다른 글
| 어텐션 메커니즘 (Attention Mechanism) (0) | 2024.10.29 |
|---|
'딥러닝 (자연어처리)' Related Articles
more

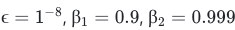{kind=link}